
この記事では、生成文法という言語学の立場から日本語の語順を分析してみたいと思います。
日本語の語順に関する最大の特徴と言えば、「語順がかなり自由」というのが真っ先に浮かんでくるでしょう。この日本語の特徴は〈かき混ぜ(スクランブリング)〉と呼ばれていて、言語学(特に構造を研究する統辞論)で活発に議論されています。
その日本語の語順に関する議論の中から今回は、〈階層分析〉と〈非階層分析〉という2つの分析の仕方とより有力とされる説の方を紹介していきます。
具体例な内容は次の通りです。
今回の内容
- 世界の言語の語順
- 日本語の語順の特徴
- 階層分析と非階層分析
- 階層分析を支持する証拠
- かき混ぜ(スクランブリング)の詳細
それでは身近な日本語に対する分析をお楽しみください。
世界の言語の基本語順の分布
多くの方がご存知だと思いますが、日本語の語順はSOV型(主語・目的語・動詞)です。
日本語の語順について分析していく前に、世界中の言語の語順について紹介しておきます。
語順の分類方法には様々ありますが、一般的にはS(Subject/主語)・O(Object/目的語)・動詞(Verb/動詞)の3個の並び方によって分類されます。「3つのものを重複なしに並べる」のですから、数学の順列の問題を考えれば、理屈的には下記の6種類(3×2×1)が考えられるわけです。
考えられる語順のパターン
- SOV
- SVO
- VSO
- VOS
- OVS
- OSV
さて実際にどの語順にどのくらいの数の言語が分類されているのでしょうか?
Dryer(2013)によると、世界の言語1377つの言語に対して研究を行い、次のような結果を提示しています。
基本語順パターンの割合
- SOV:約41%(565言語)
- SVO:約35%(488言語)
- VSO:約7%(95言語)
- VOS:約2%(25言語)
- OVS:約1%(11言語)
- OSV:約0.07%(4言語)
- 基本語順なし:約14%(189言語)
この結果からわかることはいくつかありますが、日本語との関連性に注目していうと、日本語が属するSOV言語はマジョリティーであるということです。
SVO型の英語を第二言語として学習すると、あたかも日本語の語順が稀であると感じる場合もありますが、実は日本語の語順こそが多数派だったのです。
語順について詳しくは下記の記事に譲ります。
日本語の語順における特徴「かき混ぜ」
上で日本語の語順は実は多数派であることをみてきましたが、日本語の語順に関して特筆すべきはその自由さです。
私達がよく知っている英語と比べてみると、その語順の自由さは際立ちます。
英語の語順
- Taro showed Ken Hanako.
- Taro showed Hanako Ken.
- Ken showed Taro Hanako.
- Ken showed Hanako Taro.
- Hanako showed Taro Ken.
- Hanako showed Ken Taro.
➤語順を入れ替えると意味が変わる
日本語の語順
- タロウがケンにハナコを見せた。
- タロウがハナコにケンを見せた。
- ケンがタロウにハナコを見せた。
- ケンがハナコにタロウを見せた。
- ハナコがタロウにケンを見せた。
- ハナコがケンにタロウを見せた。
➤語順を入れ替えても意味が変わらない
日本語では、動詞の後以外だったら構成素の並びを入れ替えることが許されています。
かき混ぜ(スクランブリング)
このような日本語で見られる構成素の順番を入れ替えることを〈かき混ぜ(スクランブリング)〉と言います。
日本語の基本語順をSOVとすると、下記のbがかき混ぜ文に当たります。
かき混ぜ文
- 母親が息子を叱った。
- 息子を母親が叱った。= かき混ぜ文
このような日本語が持つ語順の自由さに対して、どのような分析をすればよいのかある時期まで活発に議論されていました。
下記では、その議論の中から2つの分析をご紹介します。
日本語の語順分析「階層分析と非階層分析」
1980年代まで〈生成文法〉という言語学の分野では、日本語の語順に対して2つの理論を立ていました。
〈階層分析〉と〈非階層分析〉です。
両者の詳細はそれぞれ見ていきますが、まずは全体像として両者の〈樹形図〉をご確認ください。
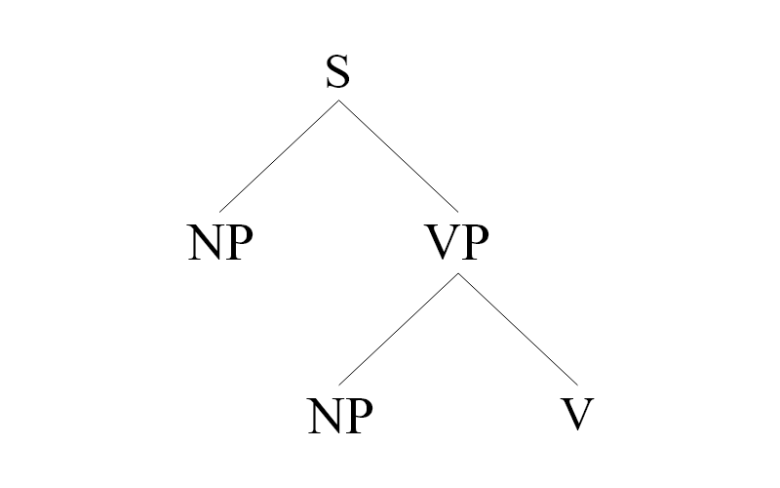
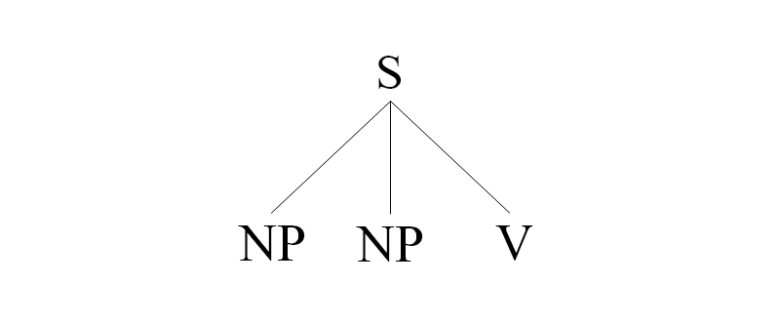
上記の樹形図は、最も一般的だと思われる構造を採用しています。生成文法の理論は時代と立場によってかなりの差異がありますが、当記事では上記の構造を採用し、具体的にはXバー理論やKP(助詞句)は採用しません。それらの理論を採用したほうが都合の良い場合も多分にありますが、今回は日本語の語順という点に注目するため、可能な限りシンプルにさせていただきます。
両者はその名の通り〈階層性〉という点で大きく異なっています。
まずはこの全体像だけ確認して、下でそれぞれの分析を具体的に見ていきましょう。
日本語の語順「階層分析」
まずは〈階層分析〉から見ていきます。
日本語の階層分析では、階層構造を仮定します。
そのため、〈主語〉と〈目的語〉という文法的役割を構造的に定義することが可能になります。
すなわち、〈主語〉とは「Sに直接支配されたNP」であり、〈目的語〉とは「VPに直接支配されたNP」という構造的定義が与えられます。
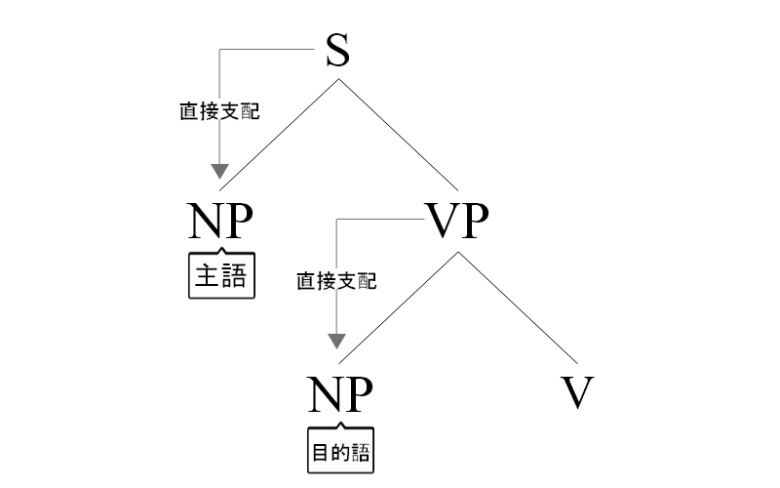
そして、上記の構造を仮定するということは、日本語の基本語順はSOV型だと想定することを意味しています。これは日本語の母語話者の直感とも一致します。
これを踏まえて、基本語順とかき混ぜ文の関係をおさえておきましょう。
階層分析における語順
- 母親が息子を叱った。(SOV)= 基本語順
- 息子を母親が叱った。(OSV) = かき混ぜ文
日本語に基本語順が存在するということは、「かき混ぜ文は基本ではない」ということを意味します。
それではかき混ぜ文はどのようにしてできあがるのでしょうか?
階層分析では、かき混ぜ文は基本語順に〈移動規則〉が適用されて生成されると考えます。
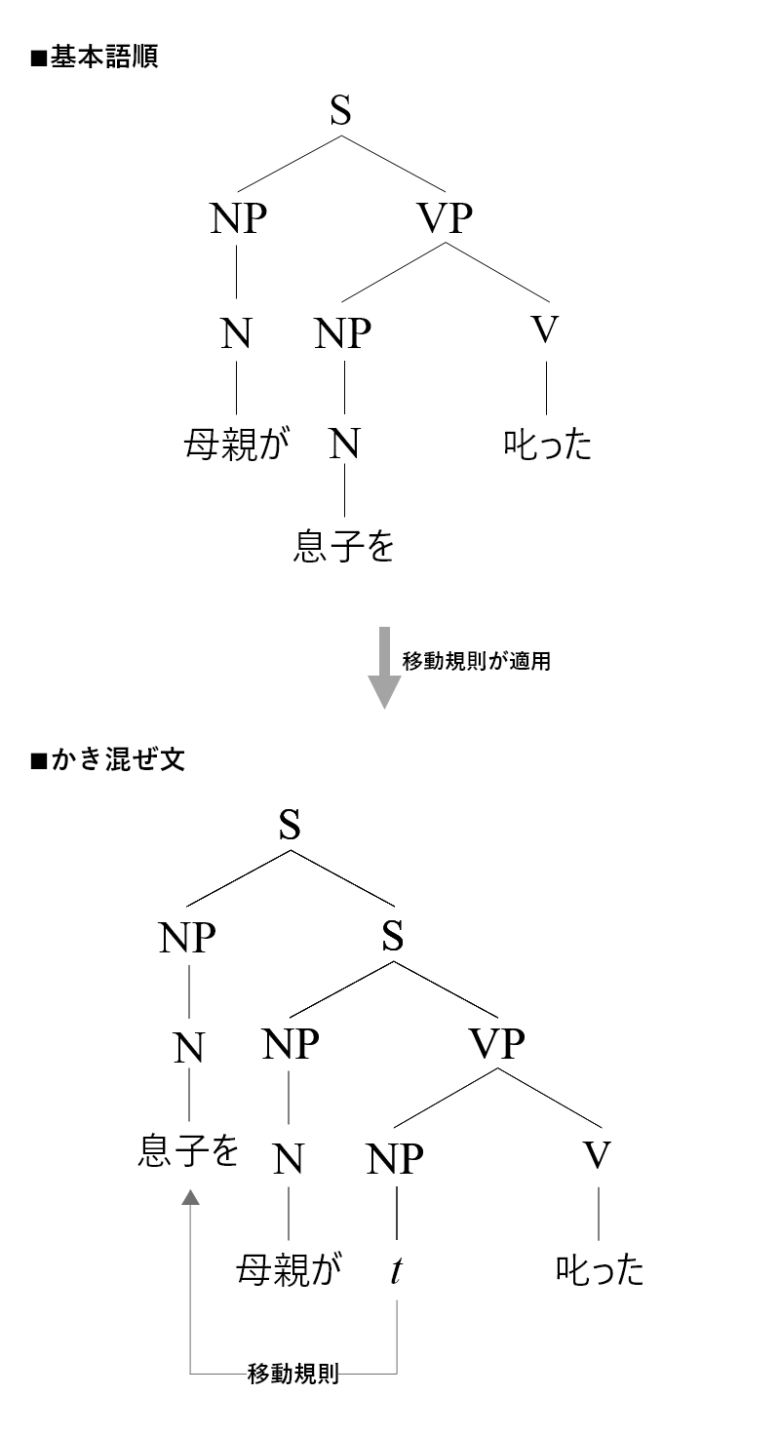
上記の2つ目の樹形図におけるtは〈痕跡〉を表しています。生成文法では、ある構成素が他の位置に移動をしたとき、元いた位置に〈痕跡〉を残すと考えられています。生成文法で痕跡を仮定する妥当性についてはこちら。
以上が〈階層分析〉におけるかき混ぜの分析でした。
■関連記事
【生成文法】痕跡(trace)の具体例と妥当性について例文でわかりやすく解説
階層分析のまとめ
階層分析でかき混ぜ文についてどのように考えるのかまとめておきます。
- 階層分析では、日本語は階層構造を持つと仮定し、基本語順はSOVだと想定する。
- 基本語順と異なる語順の文(かき混ぜ文)は、移動規則が適用されて、その移動対象となる構成素を移動箇所に前置し、元いた位置に痕跡を残すと考える。
このポイントはこれから見る〈非階層分析〉と比較すると対照的です。このことを意識して下記をご覧ください。
日本語の語順「非階層分析」
次に〈非階層分析〉を見ていきます。
日本語の非階層分析では、階層構造を仮定しません。
2つのNPとVが並列しているので、2つのNPのどっちが主語でどっちが目的語なのか構造的に定義することはできません。
つまり、非階層分析に基づけば、「日本語には基本語順はない」となるわけです。そもそも基本語順とはSOV(主語・目的語・動詞)の順番によって定まるので、主語と目的語を定義できない非階層分析のもとでは基本語順も定まらないのは当然です。
このように考える非階層分析では、下記の2つの文をどのように考えるのでしょうか?
非階層分析
- 母親が息子を叱った。
- 息子を母親が叱った。
結論としては、両者は同じ構造を持ち、どっちが「基本的」とか「構成素が移動する」とかいうことは考えません。
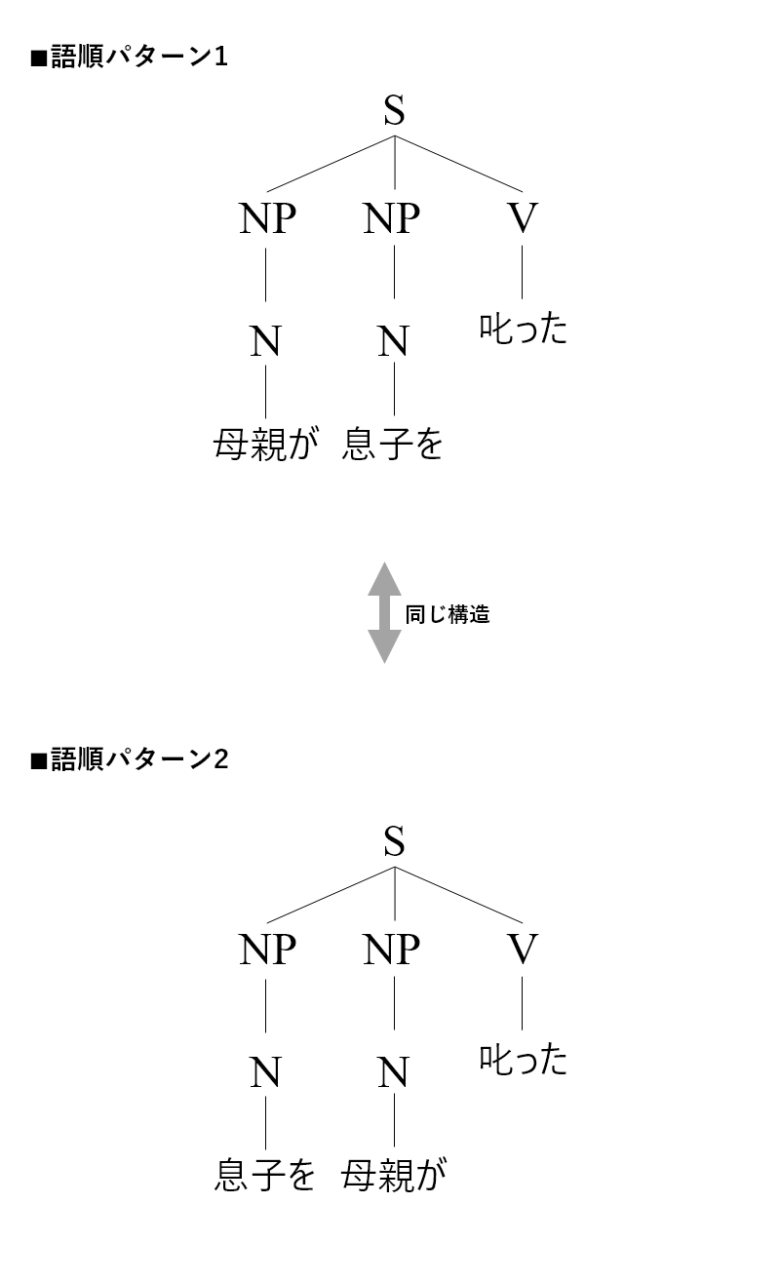
つまり、それぞれのNPに入る名詞が異なるだけで、構造自体は同じと考えます。
以上が〈非階層分析〉におけるかき混ぜの分析でした。
非階層分析のまとめ
非階層分析で日本語の語順についてどのように考えるのかまとめておきます。
- 非階層分析では、日本語は階層構造を持たないと仮定し、基本語順も想定しない。
- 非階層分析では、語順の特殊性を想定しないで、階層分析ではかき混ぜ文と呼ばれる文と基本語順は互いに区別をせず、同じ構造を持つと想定する。
先にみた〈階層分析〉ときれいに対照的なことがわかると思います。
支持されている語順分析は階層分析
ここまで日本語の語順の自由さを説明するために〈階層分析〉と〈非階層分析〉という2つの分析を見てきました。
〈階層分析〉の方では、語順が基本語順から異なったかき混ぜ文は移動規則によって説明しようとしていますが、一方で〈非階層分析〉ではそももそかき混ぜ文という語順の特殊性を想定しないという考え方をしています。
さて、互いに対照的な2つの理論ですが、言語学でより支持されている方はどちらでしょうか?
支持されている理論は〈階層分析〉です。
支持されている理由は、〈階層分析〉日本語に見られる現象や制限の方がより十分に記述・説明することができるからです。
ここでは個別の日本語の事例を取り上げることはできませんが、〈階層構造〉を支持する言語事例として下記のようなものがあります。
階層分析を支持する証拠
- 数量詞の移動
- 代名詞の指示関係
言語学に限った話ではありませんが、科学の世界で優れた理論というものは、1つの理論でより多くの事象を画一的/統合的に記述できる理論です。日本語の生成文法では、〈階層構造〉という1つの分析を採用することで、上記の数量詞や代名詞の性質を統合的に説明することができます。
そういった理由で、日本語の研究では(少なくとも非階層分析よりも)〈階層分析〉が支持されています。
全体のまとめ
今回は、日本語の語順を生成文法の立場から分析してみました。
生成文法では日本語の語順に対して〈階層分析〉と〈非階層分析〉の2つの分析が提案されてきました。
両者の決定的な違いは階層構造を想定するかという点であり、その結果、主語と目的語の構造的定義が与えられたり与えられなかったり、それ故基本語順を想定するかしないかなどの違いが生まれてきます。
最後に、日本語のかき混ぜと2つの理論をおさらいしておきましょう。
〈かき混ぜ文〉というものを想定するのは〈階層分析〉だけになります。
■参考文献
- Dryer, Matthew S. & Haspelmath, Martin (eds.) 2013. The World Atlas of Language Structures Online. Leipzig: Max Planck Institute for Evolutionary Anthropology. (Available online at http://wals.info, Accessed on 2022-12-20.)
他の日本語学に対する生成文法の記事は下記からご覧いただけます。
コメント